
Terug naar het overzicht
08 oktober 2020
SharePoint Syntex: Microsoft implementeert AI die documenten automatisch categoriseert.
Microsoft’s SharePoint Syntex is een nieuwe functie van SharePoint online die belooft metadata automatisch uit documenten te halen, waardoor het gemakkelijker wordt om informatie te vinden en te categoriseren.
SharePoint Syntex, momenteel in preview, maar met algemene beschikbaarheid beloofd voor 1 oktober, is het eerste product op basis van een bredere technologie die werd onthuld tijdens het Ignite-evenement van 2019 genaamd Project Cortex.
Het kernidee is om AI te gebruiken om inhoud te parseren die is opgeslagen in de cloud van Microsoft, niet alleen op basis van de woorden, afbeeldingen en links in de documenten, maar ook op andere signalen in de Microsoft Graph, zoals wie zich bezighoudt met de inhoud en wat afdelingen waar ze zich bevinden.
Microsoft zei dat na te hebben gezien hoe Project Cortex werd gebruikt met preview-klanten, het heeft besloten om meerdere projecten op basis van de technologie te hebben in plaats van één. SharePoint Syntex is de eerste, een premium add-on voor SharePoint online die is gericht op het gebruik van AI om het begrip en automatisering van inhoud te automatiseren, zoals het doorsturen van een document naar de juiste persoon voor goedkeuring.
Dit is niet de eerste keer dat we AI zien toegepast op SharePoint-inhoud. Microsoft introduceerde in 2014 Office Delve, ook gebaseerd op de Office Graph, met de theorie dat het gebruikers automatisch de documenten laat zien die voor hen het meest relevant zijn. Delve heeft weinig impact gehad – zal Syntex anders zijn?
Het is nog vroeg, maar Syntex is ambitieuzer dan Delve. Delve was gericht op het naar boven halen van relevante inhoud voor een gebruiker, terwijl Syntex metadata kan toevoegen aan documenten die in theorie aanzienlijke handmatige inspanningen kunnen besparen. Syntex zou een inkooporder kunnen analyseren, bijvoorbeeld de geldwaarde, de klant en de regio waar de klant is gevestigd, kunnen berekenen, en een ander proces zou het kunnen doorsturen naar het juiste team om de order te verwerken.
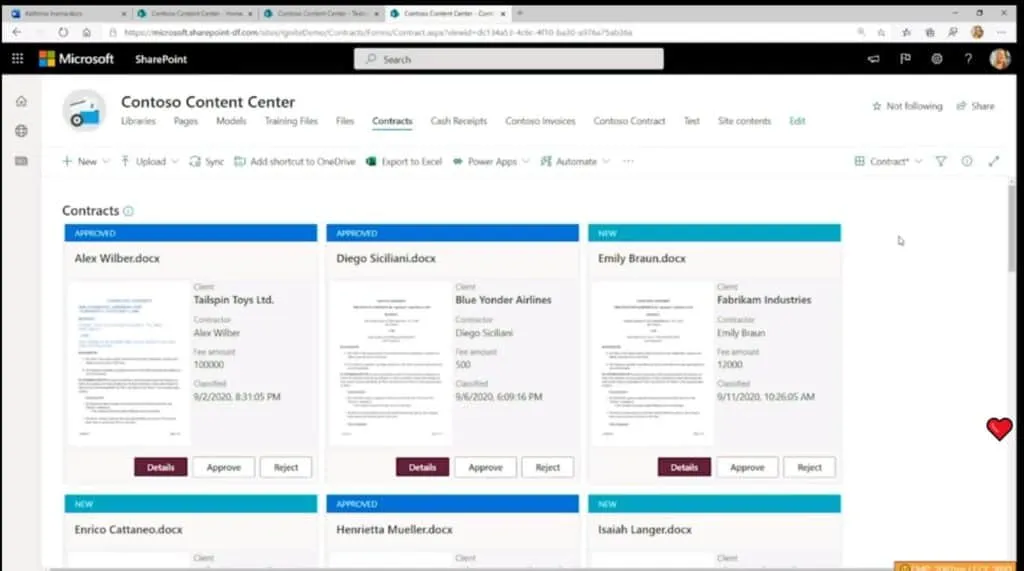
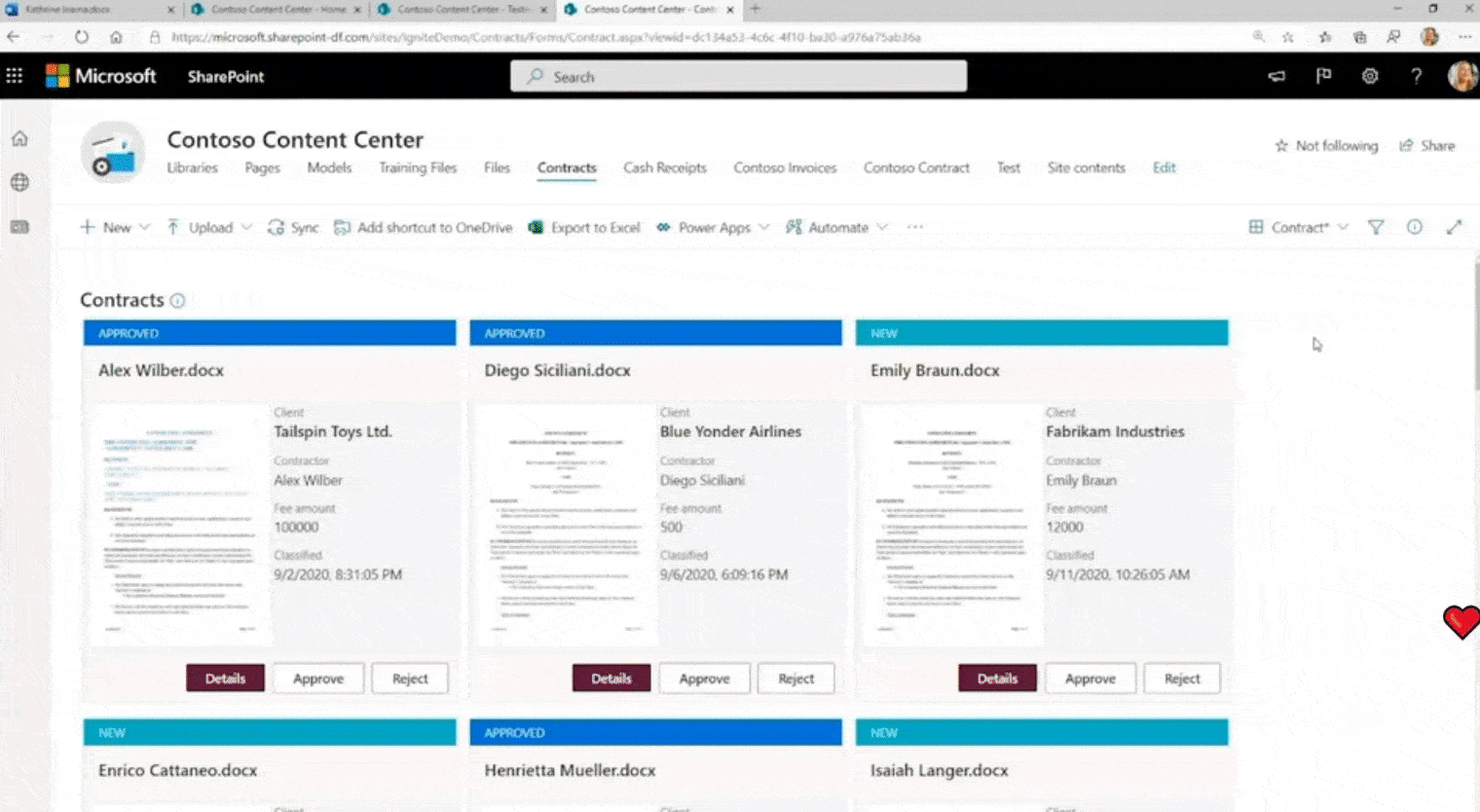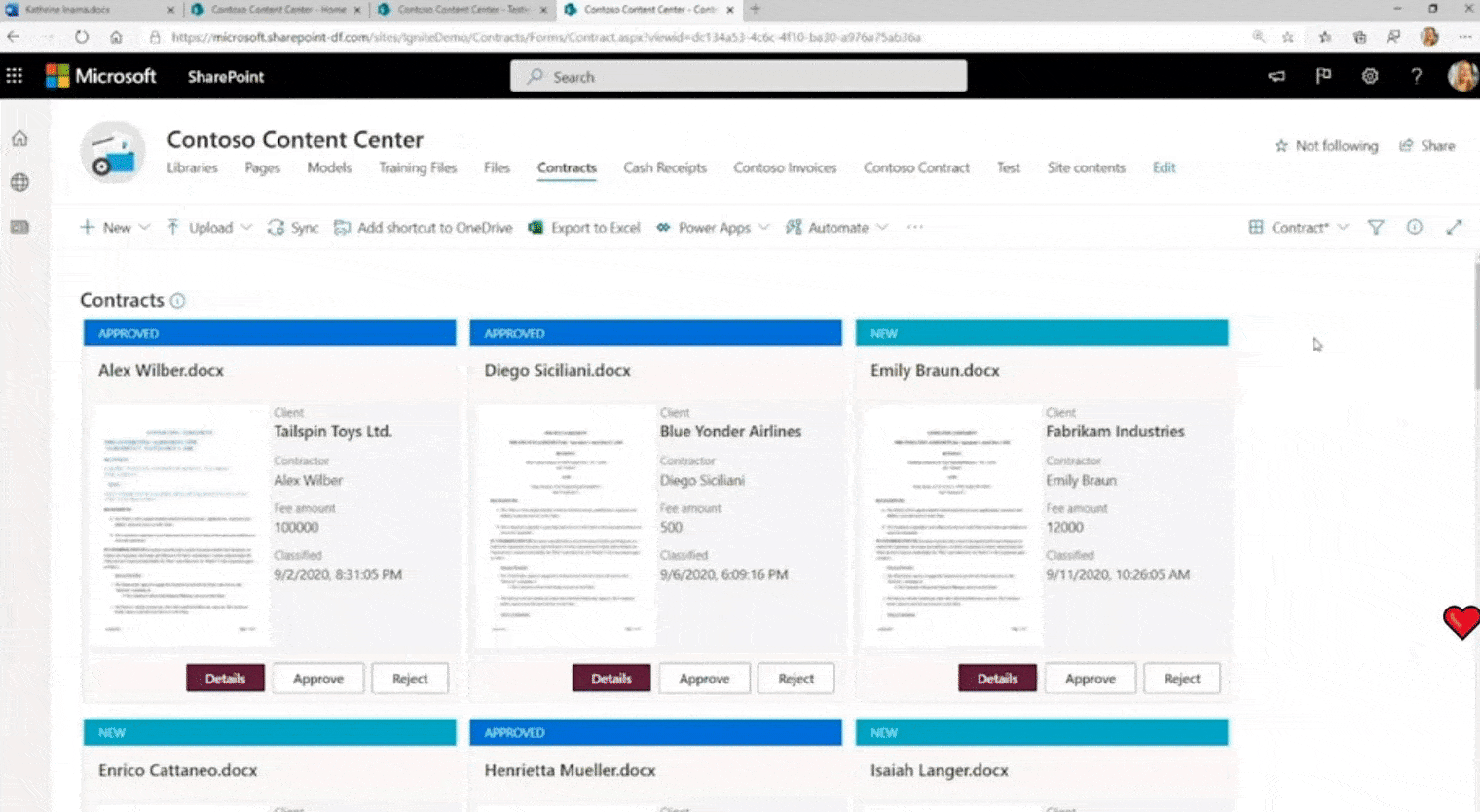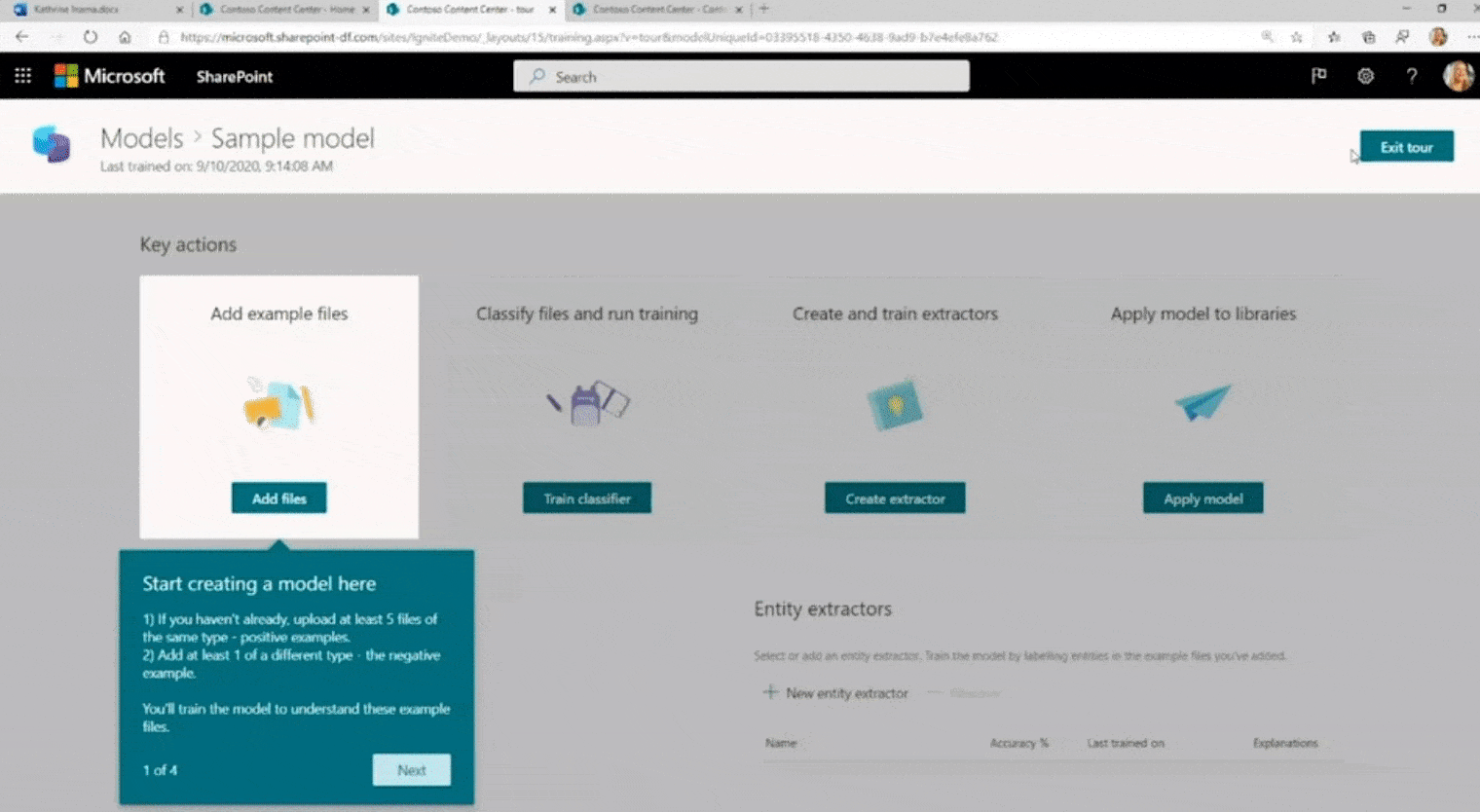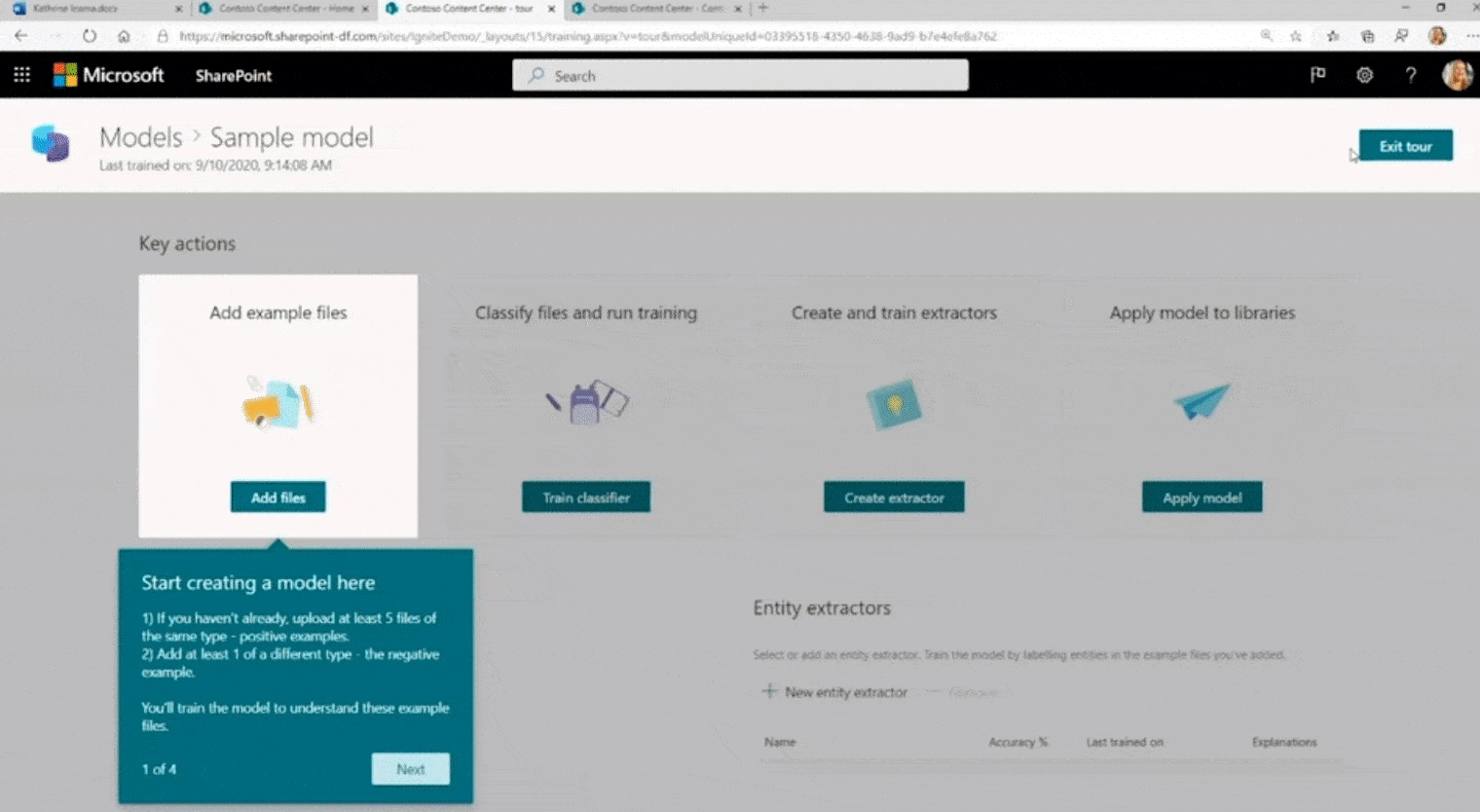
Volgens algemeen directeur Seth Patton verwerkt Syntex drie verschillende soorten inhoud: afbeeldingen, formulieren en ongestructureerde documenten. Het zal afbeeldingen labelen met “duizenden algemeen herkende objecten”, tags maken door handgeschreven tekst te herkennen en de velden in formulieren lezen, inclusief het parseren van datums, nummers, namen en adressen.
Syntex-documenten worden opgedoken in een nieuw Content Center, dat documenten in bibliotheken sorteert en de metadata die het heeft geëxtraheerd als kolommen toont. Syntex-tagging kan ook worden gebruikt voor compliance, het toevoegen van retentie- of gevoeligheidslabels en het instellen van zaken als codering, deelbeperkingen en beleid voor voorwaardelijke toegang.
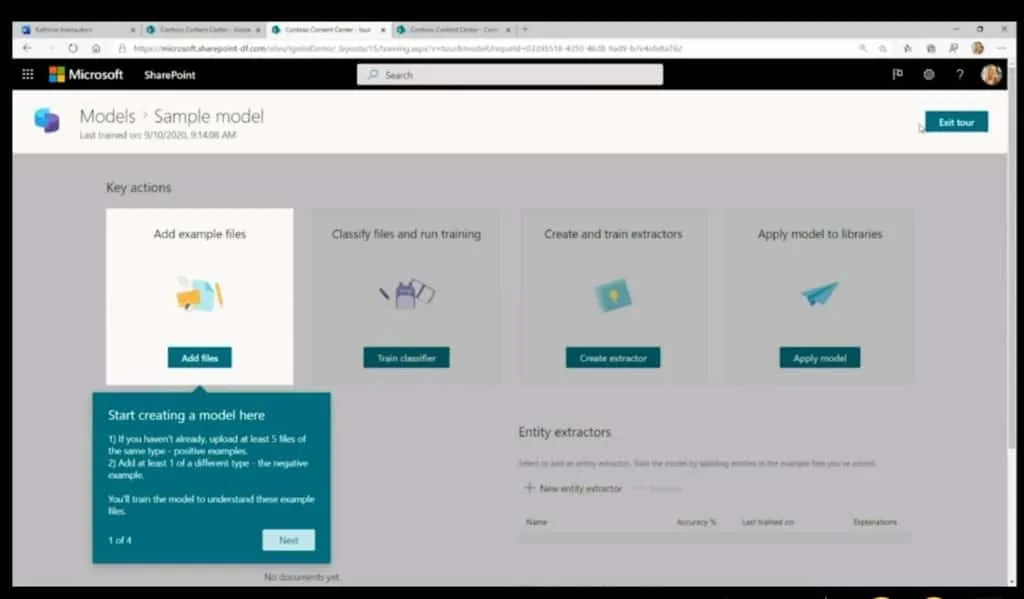
Het meest intrigerende deel van Syntex is de mogelijkheid om nieuwe modellen te trainen voor het extraheren van metadata uit documenten. Elk bedrijf heeft zijn eigen voorwaarden en categorieën. Syntex heeft een functie voor het maken van modellen waarmee u entiteiten kunt definiëren, zoals “Aannemer” of “Vergoedingbedrag”, bestaande documenten kunt markeren met labels die de waarden voor deze entiteiten identificeren, en deze kunt indienen om een model te trainen waarmee AI ze automatisch kan extraheren van nieuwe documenten.
Slechts vijf bestanden om het model te trainen
Naomi Moneypenny, directeur programmabeheer voor Syntex, zei bij Ignite dat slechts vijf bestanden voldoende kunnen zijn voor training, vooral als gebruikers zowel positieve als negatieve voorbeelden van een bepaald inhoudstype aanleveren. Formulierverwerking, die het gemakkelijkste type inhoud zou moeten zijn waaruit metagegevens kunnen worden geëxtraheerd, heeft een specifieke formulierverwerkingsengine.
Content die door Syntex wordt verwerkt, hoeft niet in SharePoint te leven, maar kan via Microsoft Graph content connectoren ook uit andere bronnen worden opgezogen. Voorbeelden van dergelijke bronnen zijn onder meer bestandsshares, Azure SQL, Box, Amazon S3, Google Drive, SharePoint on-premises en Salesforce.
Microsoft sprak op Ignite over nieuwe functies die gepland zijn voor Syntex begin volgend jaar, waaronder uitgebreide modeltypes, centraal modelbeheer, op Syntex gebaseerde oplossingen voor verwerkte bedrijven en meer integratie tussen Syntex en “kennisverbeteringen in Microsoft 365”.
Allemaal een beetje vaag, maar je krijgt de indruk dat het bedrijf AI-gestuurde contentanalyse als een belangrijk onderdeel van zijn 365-aanbod ziet.
Terwijl Delve gratis was voor gelicentieerde SharePoint-gebruikers, is Syntex een betaalde service die beschikbaar is voor E3- of E5-abonnees van Microsoft 365. De prijzen zien er complex uit, zijn per gebruiker en beperkt tot “500 items geïndexeerd door contentconnector, gepoold”, aldus naar een dia gepresenteerd op Ignite. Klanten krijgen ook credits voor het verwerken van formulieren. Vermoedelijk zijn er extra kosten van toepassing als deze limieten worden overschreden.
Het probleem met al het bovenstaande is of het bedrijf te veelbelovend is als het gaat om de voordelen van Syntex. Gezien de complexiteit van de onderliggende datawetenschap, lijdt het geen twijfel over het vermogen van het bedrijf om het gebruik van AI-services te vereenvoudigen, of dit nu in Syntex is of in zijn andere Cognitive Services-portfolio.
AI is echter een inherent onvolmaakte technologie, die in een zakelijke context zorgwekkend is als organisaties er te veel van afhankelijk zijn, bijvoorbeeld om te beslissen of een document al dan niet vertrouwelijk is. Als betaalde dienst zal Syntex een voldoende hoge nauwkeurigheid moeten leveren om zijn kosten te rechtvaardigen.
Of Syntex nu vliegt of niet, je kunt er zeker van zijn dat Microsoft, net als anderen op het gebied van documentbeheer, AI-technologie zal blijven toepassen in de hoop deze opslagplaatsen van ongestructureerde gegevens beter te begrijpen.
Bron: theregister
Meer weten?
Gerelateerde
blogs










Tech Updates: Microsoft 365, Azure, Cybersecurity & AI – Wekelijks in je Mailbox.