
Knowledge base
October 08, 2020
SharePoint Syntex: Microsoft implements AI that automatically categorizes documents.
Microsoft’s SharePoint Syntex is a new feature of SharePoint online that promises to automatically extract metadata from documents, making it easier to find and categorize information.
SharePoint Syntex, currently in preview but with general availability promised for October 1, is the first product based on a broader technology unveiled at the 2019 Ignite event called Project Cortex.
The core idea is to use AI to parse content stored in Microsoft’s cloud, not only based on the words, images, and links in the documents, but also on other signals in the Microsoft Graph, such as who deals with the content and what departments where they are located.
Microsoft said that after seeing how Project Cortex was used with preview customers, it has decided to have multiple projects based on the technology instead of one. SharePoint Syntex is the first, a premium add-on for SharePoint online that focuses on using AI to automate the understanding and automation of content, such as forwarding a document to the right person for approval.
This isn’t the first time we’ve seen AI applied to SharePoint content. Microsoft introduced Office Delve in 2014, also based on the Office Graph, with the theory that it automatically shows users the documents that are most relevant to them. Delve has had little impact – will Syntex be different?
It’s early days, but Syntex is more ambitious than Delve. Delve was focused on bringing out relevant content for a user, while Syntex can add metadata to documents that could theoretically save significant manual efforts. Syntex could analyze a purchase order, for example, calculate the monetary value, the customer and the region where the customer is located, and another process could forward it to the right team to process the order.
According to general manager Seth Patton, Syntex processes three different types of content: images, forms, and unstructured documents. It will tag images with “thousands of commonly recognized objects,” create tags by recognizing handwritten text, and read the fields in forms, including parsing dates, numbers, names, and addresses.
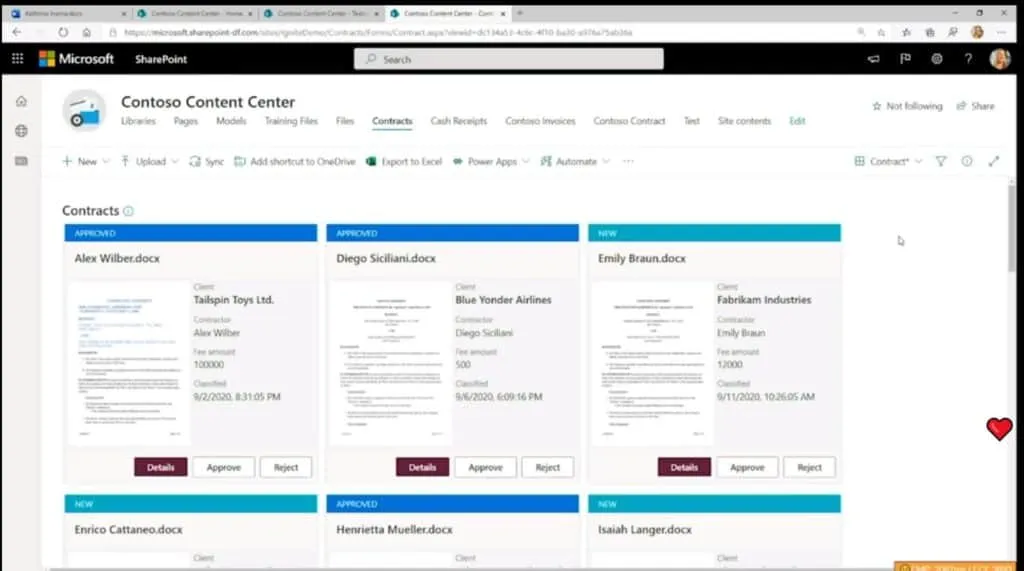
Syntex documents are turned up in a new Content Center, which sorts documents into libraries and shows the metadata it has extracted as columns. Syntex tagging can also be used for compliance, adding retention or sensitivity labels, and setting things like encryption, partial restrictions, and conditional access policies.
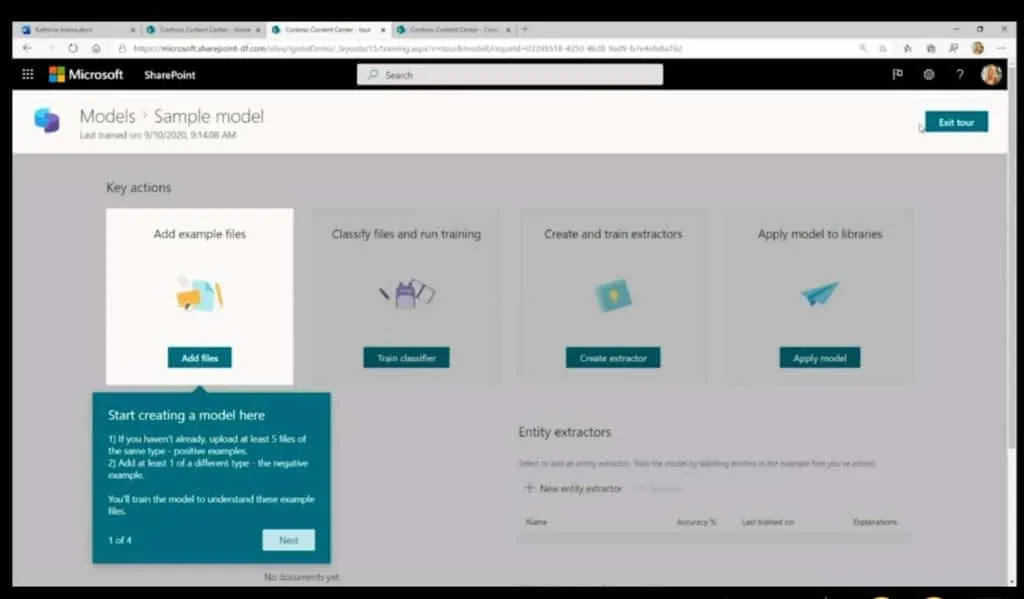
The most intriguing part of Syntex is the ability to train new models to extract metadata from documents. Each company has its own terms and categories. Syntex has a model creation feature that allows you to define entities, such as “Contractor” or “Compensation Amount,” flag existing documents with labels that identify the values for those entities, and submit them to train a model that allows AI to automatically extract them from new documents.
Only five files to train the model
Naomi Moneypenny, director of program management for Syntex, said at Ignite that only five files can be enough for training, especially if users provide both positive and negative examples of a particular content type. Form processing, which should be the easiest type of content from which metadata can be extracted, has a specific form processing engine.
Content processed by Syntex doesn’t have to live in SharePoint, but can also be sucked up from other sources through Microsoft Graph content connectors. Examples of such resources include file shares, Azure SQL, Box, Amazon S3, Google Drive, SharePoint on-premises, and Salesforce.
Microsoft spoke at Ignite about new features planned for Syntex early next year, including expanded model types, central model management, Syntex-based solutions for processed businesses, and increased integration between Syntex and “knowledge improvements in Microsoft 365.”
All a bit sketchy, but you get the impression that the company sees AI-driven content analysis as an important part of its 365 offering.
While Delve was free for licensed SharePoint users, Syntex is a paid service available to Microsoft 365 E3 or E5 subscribers. The prices look complex, are per user and limited to “500 items indexed by content connector, pooled,” according to a slide presented on Ignite. Customers also receive credits for processing forms. Presumably, additional charges will apply if these limits are exceeded.
The problem with all of the above is whether the company is too promising when it comes to the benefits of Syntex. Given the complexity of underlying data science, there is no doubt about the company’s ability to simplify the use of AI services, whether in Syntex or in its other Cognitive Services portfolio.
However, AI is an inherently imperfect technology, which is worrisome in a business context when organizations rely too much on it, for example to decide whether or not a document is confidential. As a paid service, Syntex will have to provide sufficiently high accuracy to justify its costs.
Whether Syntex flies or not, you can be sure that Microsoft, like others in document management, will continue to apply AI technology in the hope of better understanding these repositories of unstructured data.
Source: theregister
Want to know more?

Related
blogs










Tech Updates: Microsoft 365, Azure, Cybersecurity & AI – Weekly in Your Mailbox.